Всем привет, уважаемые читатели блога DmitriyZhilin.ru. В данной статье я рассмотрю очень важный вопрос, относящийся к теме внутренней оптимизации, который определит будущее развитие ресурса и успех в его продвижении. Поговорим с вами о таком понятии, как дубли страниц на сайте. Я покажу как искать одинаковые страницы и как удалить дубли с сайта.

Категории дублей страниц
На сегодняшний день различают два вида дублей — полные (четкие) и нечеткие.
Полный (четкий) дубль — это страницы на одном сайте содержащие полностью идентичный (одинаковый) контент, но имеющие различные URL адреса (например, страницы пагинации).
Не полный (нечеткий) дубль — это страницы, часть содержимого которых совпадает, а часть отличается (например, архивы записей, архивы авторов).
Их наличие может привести к ухудшению индексации, читайте пост “Почему сайт не индексируется поисковыми системами”, проседанию позиций в поисковой выдаче и к наложению фильтров.
Появление дублей страниц на сайте может быть обусловлено различными причинами.
- Технические недоработки. Что включает в себя наличие битых ссылок, неправильный файл robots.txt, не настроенный 301 редирект с домена с www на без www и на удаленные страницы.
- Ошибки оптимизатора. Влияние на поисковые машины и черная seo оптимизация. Некоторые вебмастера сознательно генерируют документы, являющиеся частичными или полными дублями, для того, чтобы было больше страниц и можно было разместить дополнительную рекламу.
- Автоматические дубли страниц. Многие CMS системы способный автоматически создавать дубли страниц на сайте без участия оптимизатора или веб — разработчика. Среди них WordPress (анонсы, архивы, страницы автора, ответы на комментарии и т.д.) и Joomla.
А теперь, уважаемые читатели, я предлагаю рассмотреть алгоритм поиска дублей страниц на сайте.
Как найти дубли страниц на сайте
Существует множество бесплатных способов, основанных как на использовании Яндекс и Google, так и с применением программных инструментов, которые анализируют доменное имя. Начну, пожалуй, с самых простых и трудоемких.
Использование поисковой системы Яндекс
Откройте поиск Яндекса. Заключите часть текста страницы, которую подозреваете в наличии копии в кавычки и отправьте такой запрос поисковой системе. Чтобы определить дубли, нажимаем значок «Расширенный поиск» и вводим адрес домена, на котором будем искать дубли. В приведенном ниже примере я взял текст с одного своего сайта, эта часть текста входит в анонс, поэтому появляется не только на странице со статьей, но и, как видите, на страницах рубрик и на главной — частичные дубли.
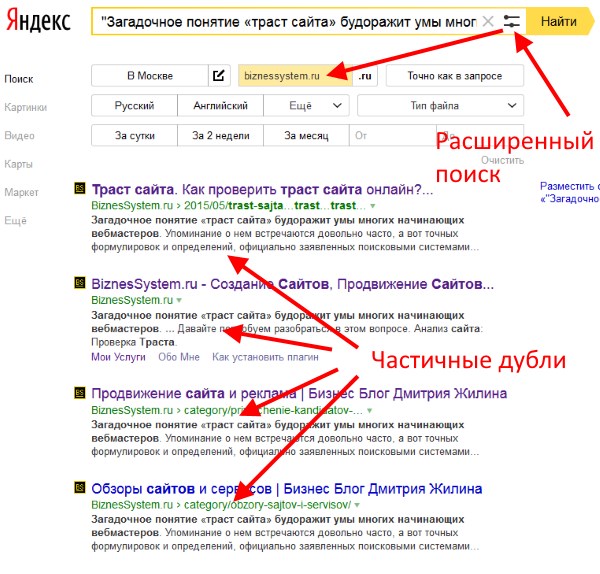
Если вы нашли частичные дубли текста из анонса, то это не критично, главное, чтобы у вас нигде не повторялся основной текст статьи. Я специально взял такой пример, чтобы показать вам — анонс статьи, отделяемый тегом <more> не должен быть большим (один абзац из 2-3 предложений).
Поиск дублей через Google
Технология поиска аналогична, только в поисковой системе Гугл для поиска по сайту используется специальный оператор. Так же, как и в предыдущем способе, копируете фрагмент текста в «кавычках» и вставляем в окно поиска Google, перед текстом напишите следующую строку site:домен-сайта.ru
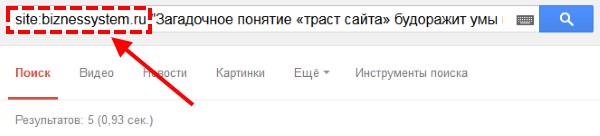
Если найдутся дубли страниц, то они появятся в выдаче. Переходим от простых и примитивных способов к использованию специализированных инструментов.
Как удалить дубли страниц на сайте
Мне известно 4 действенный способа удаления дублей страниц на сайте и сейчас я вам о них расскажу.
1. Удаление первопричины. Вам нужно найти функцию вашего сайта, которая создает дубликаты текстов. Например, стандартные древовидные комментарии WordPress создают дубли статей с адресом заканчивающимся на replytocom — чтобы от них избавиться нужно отключить древовидные комментарии или изменить функцию вывода комментариев. подробная статья на эту тему есть здесь.
2. Использование канонических URL и тегов noindex/nofollow. Тег rel=”canonical”, указывает поисковым машинам, какая страница из всех дублей является канонической (главной). Можно настроить этот параметр через плагин All in One SEO Pack.

В этом же плагине можно указать разделы сайта, которые индексироваться не должны.
3. Директива Disallow. Данный способ не удаляет сами дубли с технической точки зрения, но говорит поисковикам, что страницы с определенными адресами индексировать не нужно. Например, если дублированные статьи находятся в какой то определенной директории, а это вы поймете, проанализировав их адрес, то можно закрыть эту директорию в robots.txt. Как настроить robots.txt я писал здесь.
4. 301 редирект. В начале статьи я уже писал о дублях сайта с www и без www, там же была ссылка на статью о том, как правильно настроить главное зеркало с помощью 301 редиректа.
Если у вас возникнут какие-нибудь вопросы о том, как найти и удалить дубли с сайта, то обращайтесь с комментариями. Чем смогу, тем помогу.
Для сайтов с большим количеством страниц будет довольно трудозатратно искать и склеивать дубли.